
Improving skill-creator: Test, measure, and refine Agent Skills
Skill authors can now verify that their skills work, catch regressions, and improve descriptions.
Skill authors can now verify that their skills work, catch regressions, and improve descriptions.
Skill-creator now helps you write evals, run benchmarks, and keep your skills working as models evolve. These updates are available now in Claude.ai and Cowork, as a plugin for Claude Code, and within our repo.
Since launching Agent Skills last October, we've noticed that most authors are subject matter experts, not engineers. They know their workflows but don't have the tools to tell whether a skill still works with a new model, triggers when it should, or if it actually improved after an edit.
Today we're announcing skill-creator enhancements that help authors build with more confidence. We are bringing some of the rigor of software development (testing, benchmarking, iterative improvement) to skill authoring without requiring anyone to write code.
Skills generally fall into two categories:
Capability uplift skills help Claude do something the base model either can't do or can't do consistently. Our document creation skills are good examples. They encode techniques and patterns that produce better output than prompting alone.
Encoded preference skills document workflows where Claude can already do each piece, but the skill sequences them according to your team's process. Examples: a skill that walks through NDA review against set criteria, or one that drafts weekly updates with data from various MCPs.
This distinction matters because these two types of skills may need testing for different reasons:
Either way, testing turns a skill that seems to work into one you know works.
Skill-creator now helps you write evals, which are tests that check Claude does what you expect for a given prompt. If you've written software tests, this will feel familiar: define some test prompts (plus files if needed), describe what good looks like, and skill-creator tells you whether the skill holds up.
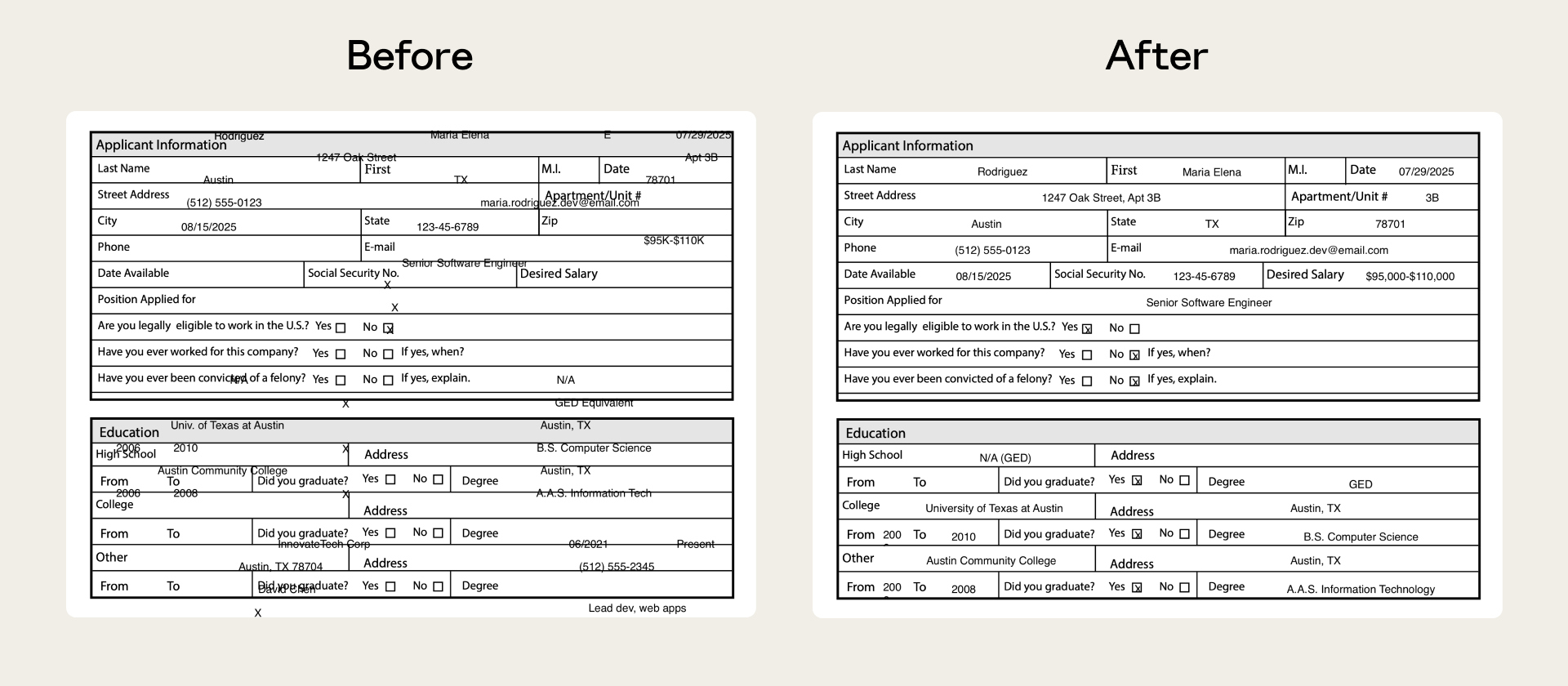
Our PDF skill, for instance, previously struggled with non-fillable forms. Claude had to place text at exact coordinates with no defined fields to guide it. Evals isolated the failure, and we shipped a fix that anchors positioning to extracted text coordinates.
Evals help in many ways, but two important uses are to catch quality regressions and understand model progress.
First, catching regressions in quality. As models and the infrastructure around them evolve, a skill that worked well last month might behave differently today. Running evals against a new model gives you an early signal when something shifts before it impacts your team’s work.
Second, knowing when general model capabilities have outgrown your skill. This applies mainly to capability uplift skills. If the base model starts passing your evals without the skill loaded, that's a signal the skill's techniques may have been incorporated into the model's default behavior. The skill isn't broken; it's just no longer necessary.
We've also added a benchmark mode that runs a standardized assessment using your evals. This is something you can run after model updates or as you iterate on the skill itself. It tracks eval pass rate, elapsed time, and token usage.
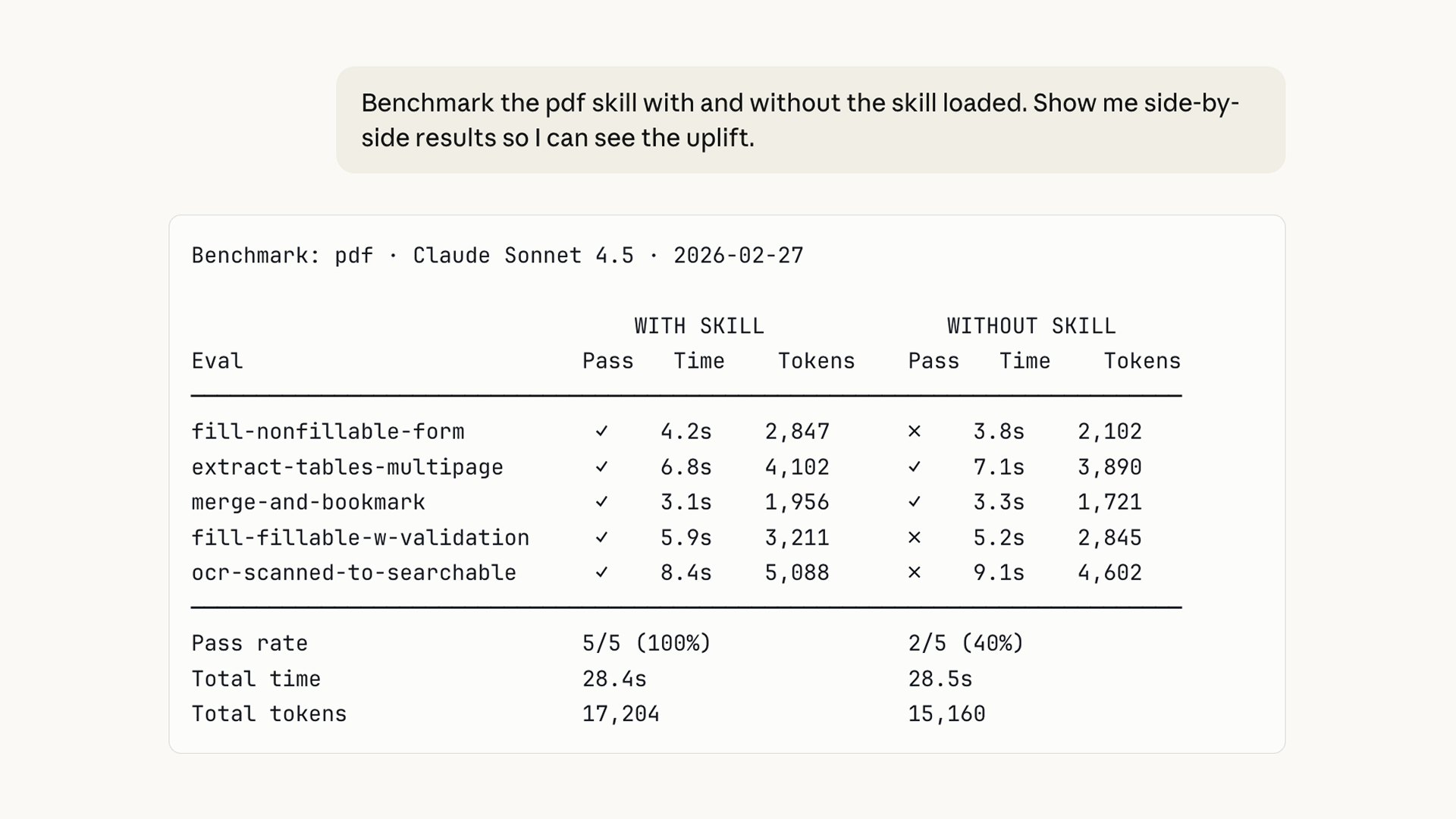
Your evals and results stay with you. Store them locally, integrate them with a dashboard, or plug them into a CI system.
Running evals sequentially can be slow, and accumulating context can bleed between test runs. Skill-creator now spins up independent agents to run evals in parallel with multi-agent support — each in a clean context with its own token and timing metrics. Faster results, no cross-contamination.
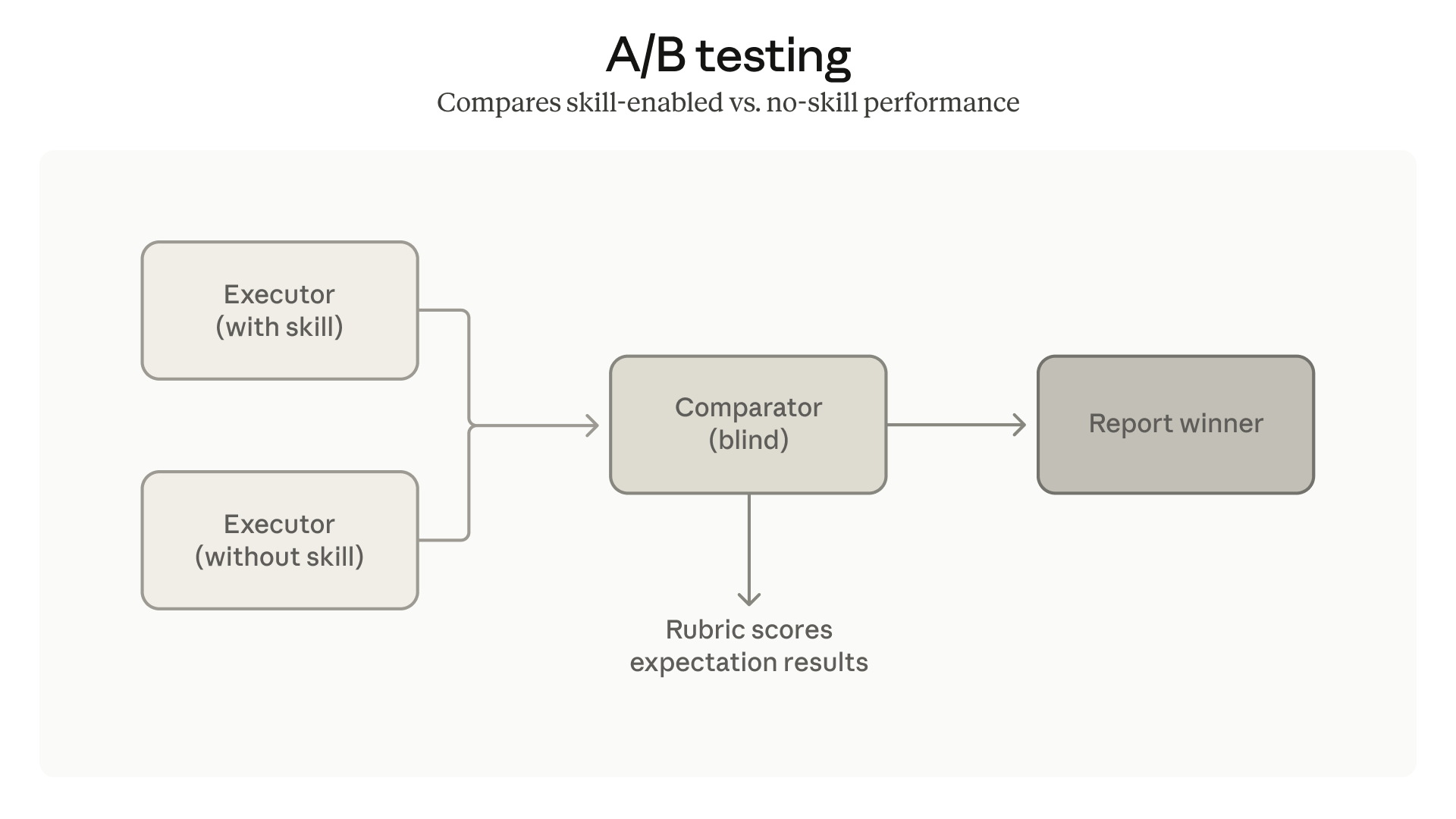
We've also added comparator agents for A/B comparisons: two skill versions, or skill vs. no skill. They judge outputs without knowing which is which, so you can tell whether a change actually helped.
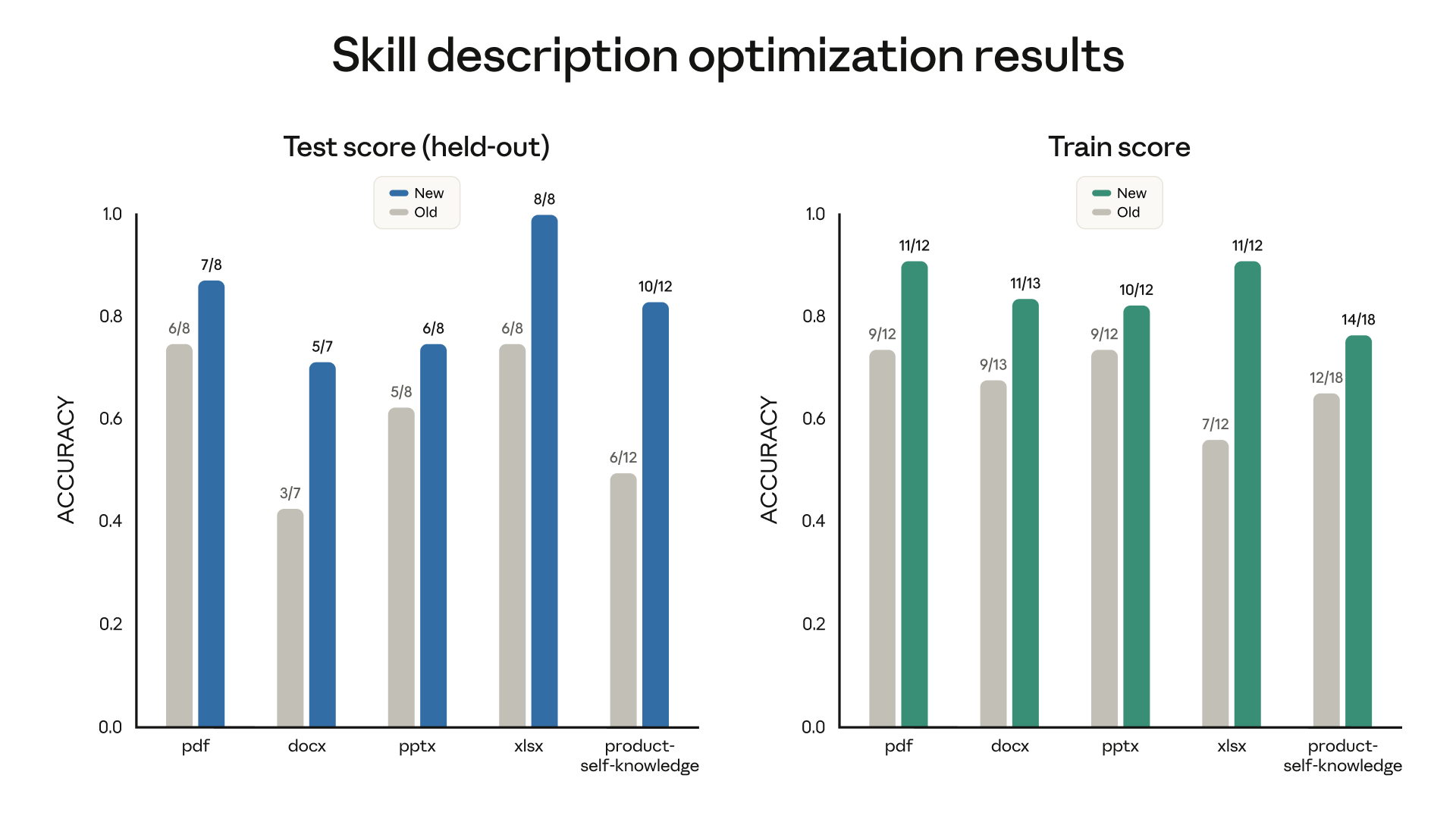
Evals measure output quality, but that only matters if your skill triggers when it should. As your skill count grows, description precision becomes critical: too broad and you get false triggers, too narrow and it never fires. Skill-creator now helps you tune descriptions for more reliable triggering — it analyzes your current description against sample prompts and suggests edits that cut both false positives and false negatives.
We ran it across our document-creation skills and saw improved triggering on 5 out of 6 public skills.
As models improve, the line between "skill" and "specification" may blur. Today, a SKILL.md file is essentially an implementation plan, providing detailed instructions telling Claude how to do something. Over time, a natural-language description of what the skill should do may be enough, with the model figuring out the rest.
The eval framework we're releasing today is a step in that direction. Evals already describe the "what." Eventually, that description may be the skill itself.
All skill-creator updates are available now on Claude.ai and Cowork. Ask Claude to use the skill-creator to get started.
Claude Code users can install the plugin or download from our repo.

Get the developer newsletter
Product updates, how-tos, community spotlights, and more. Delivered monthly to your inbox.



