
Multi-agent coordination patterns: Five approaches and when to use them
Five multi-agent coordination patterns, their trade-offs, and when to evolve from one to another.
Five multi-agent coordination patterns, their trade-offs, and when to evolve from one to another.
In an earlier post, we explored when multi-agent systems provide value and when a single agent is the better choice. This post is for teams that have made that call and now need to decide which coordination pattern fits their problem.
We've seen teams choose patterns based on what sounds sophisticated rather than what fits the problem at hand. We recommend starting with the simplest pattern that could work, watching where it struggles, and evolving from there. This post examines the mechanics and limitations of five patterns:
This is the simplest multi-agent pattern and among the most deployed. We introduced it as the verification subagent pattern in our previous post, and here we use the broader generator-verifier framing because the generator need not be an orchestrator.
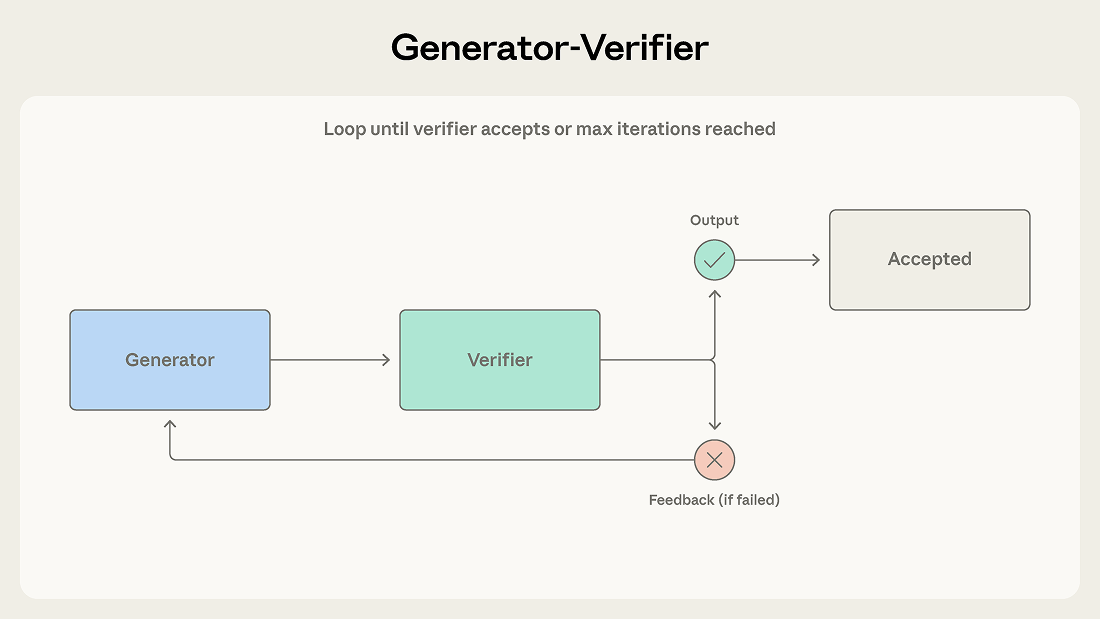
A generator receives a task and produces an initial output, which it passes to a verifier for evaluation. The verifier checks whether the output meets the required criteria and either accepts it as complete or rejects it with feedback. If rejected, that feedback is routed back to the generator, which uses it to produce a revised attempt. This loop continues until the verifier accepts the output or the maximum number of iterations is reached.
Consider a support system that generates email responses to customer tickets. The generator produces an initial response using product documentation and ticket context. The verifier checks accuracy against the knowledge base, evaluates tone against brand guidelines, and confirms the response addresses each issue raised. Failed checks return to the generator with feedback that names the exact problem, such as a feature misattributed to the wrong pricing tier or a ticket issue left unanswered.
Use this pattern when output quality is critical and evaluation criteria can be made explicit. It’s effective for code generation (one agent writes code, another writes and runs tests), fact-checking, rubric-based grading, compliance verification, and any domain where an incorrect output costs more than an additional generation cycle.
The verifier is only as good as its criteria. A verifier told only to check whether output is good, with no further criteria, will rubber-stamp the generator's output. Teams most often fail by implementing the loop without defining what verification means, which creates the illusion of quality control without the substance. (We discussed this early victory problem in the previous post.)
The pattern also assumes generation and verification are separable skills. If evaluating a creative approach is as hard as generating one, the verifier may not reliably catch problems.
Finally, iterative loops can stall. If the generator can't address the verifier's feedback, the system oscillates without converging. A maximum iteration limit with a fallback strategy (escalate to a human, return the best attempt with caveats) prevents this from becoming an infinite loop.
Hierarchy defines this pattern. One agent acts as a team lead that plans work, delegates tasks, and synthesizes results. Subagents handle specific responsibilities and report back.
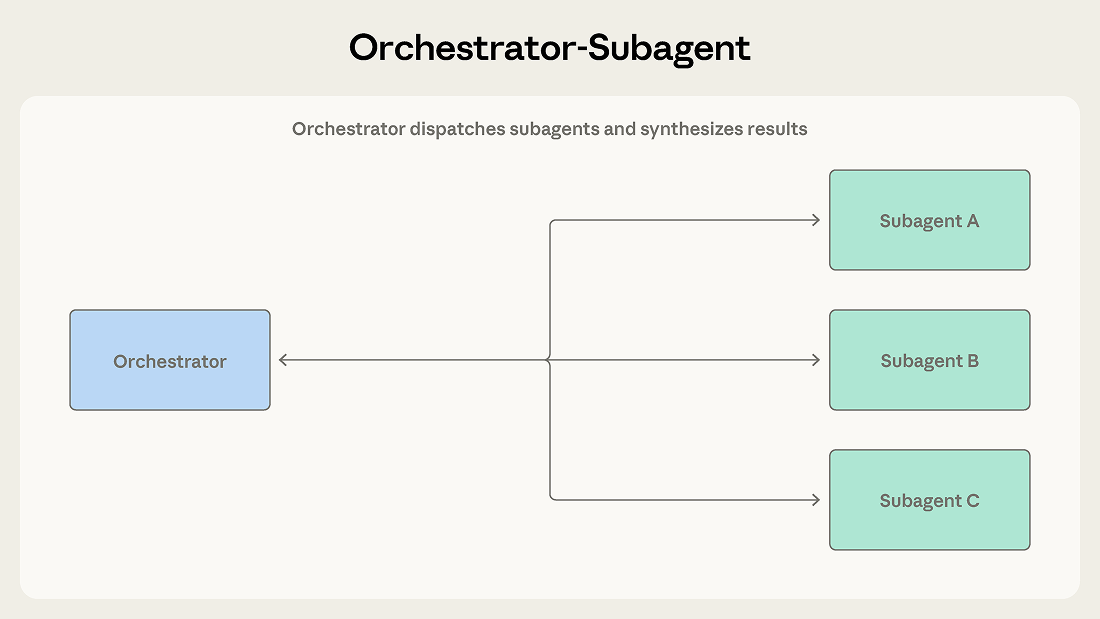
A lead agent receives a task and determines how to approach it. It may handle some subtasks directly while dispatching others to subagents. Subagents complete their work and return results, which the orchestrator synthesizes into a final output.
Claude Code uses this pattern. The main agent writes code, edits files, and runs commands itself, dispatching subagents in the background when it needs to search a large codebase or investigate independent questions so work continues while results stream back. Each subagent operates in its own context window and returns distilled findings. This keeps the orchestrator's context focused on the primary task while exploration happens in parallel.
Consider an automated code review system. When a pull request arrives, the system needs to check for security vulnerabilities, verify test coverage, assess code style, and evaluate architectural consistency. Each check is distinct, requires different context, and produces a clear output. An orchestrator dispatches each check to a specialized subagent, collects the results, and synthesizes a unified review.
Use this pattern when task decomposition is clear and subtasks have minimal interdependence. The orchestrator maintains a coherent view of the overall goal while subagents stay focused on specific responsibilities.
The orchestrator becomes an information bottleneck. When a subagent discovers something relevant to another subagent's work, that information has to travel back through the orchestrator. If the security subagent finds an authentication flaw that affects the architecture subagent's analysis, the orchestrator must recognize this dependency and route the information appropriately. After several such handoffs, critical details are often lost or summarized away.
Sequential execution also limits throughput. Unless explicitly parallelized, subagents run one after another, meaning the system incurs multi-agent token costs without the speed benefit.
When work decomposes into parallel subtasks that can proceed independently for extended periods, orchestrator-subagent can become unnecessarily constraining.
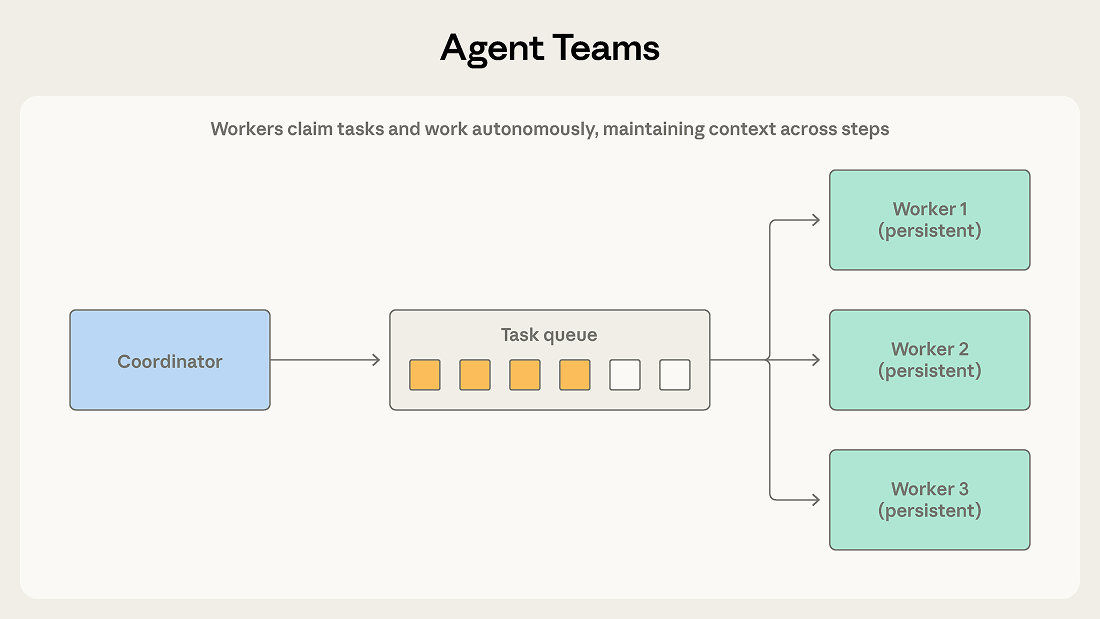
A coordinator spawns multiple worker agents as independent processes. Teammates claim tasks from a shared queue, work on them autonomously across multiple steps, and signal completion.
The difference from orchestrator-subagent is worker persistence. The orchestrator spawns a subagent for one bounded subtask, and the subagent terminates after returning a result. Teammates stay alive across many assignments, accumulating context and domain specialization that improve their performance over time. The coordinator assigns work and collects outcomes but doesn’t reset workers between tasks.
Consider migrating a large codebase from one framework to another. A teammate can migrate each service independently, with its own dependencies, test suite, and deployment configuration. A coordinator assigns each service to a teammate, and each teammate works through the migration autonomously: dependency updates, code changes, test fixes, validation. The coordinator collects completed migrations and runs integration tests across the full system.
Use this pattern when subtasks are independent and benefit from sustained, multi-step work. Each teammate builds up context about its domain rather than starting fresh with each dispatch.
Independence is the critical requirement. Unlike orchestrator-subagent, where the orchestrator can mediate between subagents and route information, teammates operate autonomously and can't easily share intermediate findings. If one teammate's work affects another's, neither is aware, and their outputs may conflict.
Completion detection is also harder. Since teammates work autonomously for variable durations, the coordinator must handle partial completion where one teammate finishes in two minutes and another takes twenty.
Shared resources compound both problems. When multiple teammates operate on the same codebase, database, or file system, two teammates may edit the same file or make incompatible changes. The pattern requires careful task partitioning and conflict resolution mechanisms.
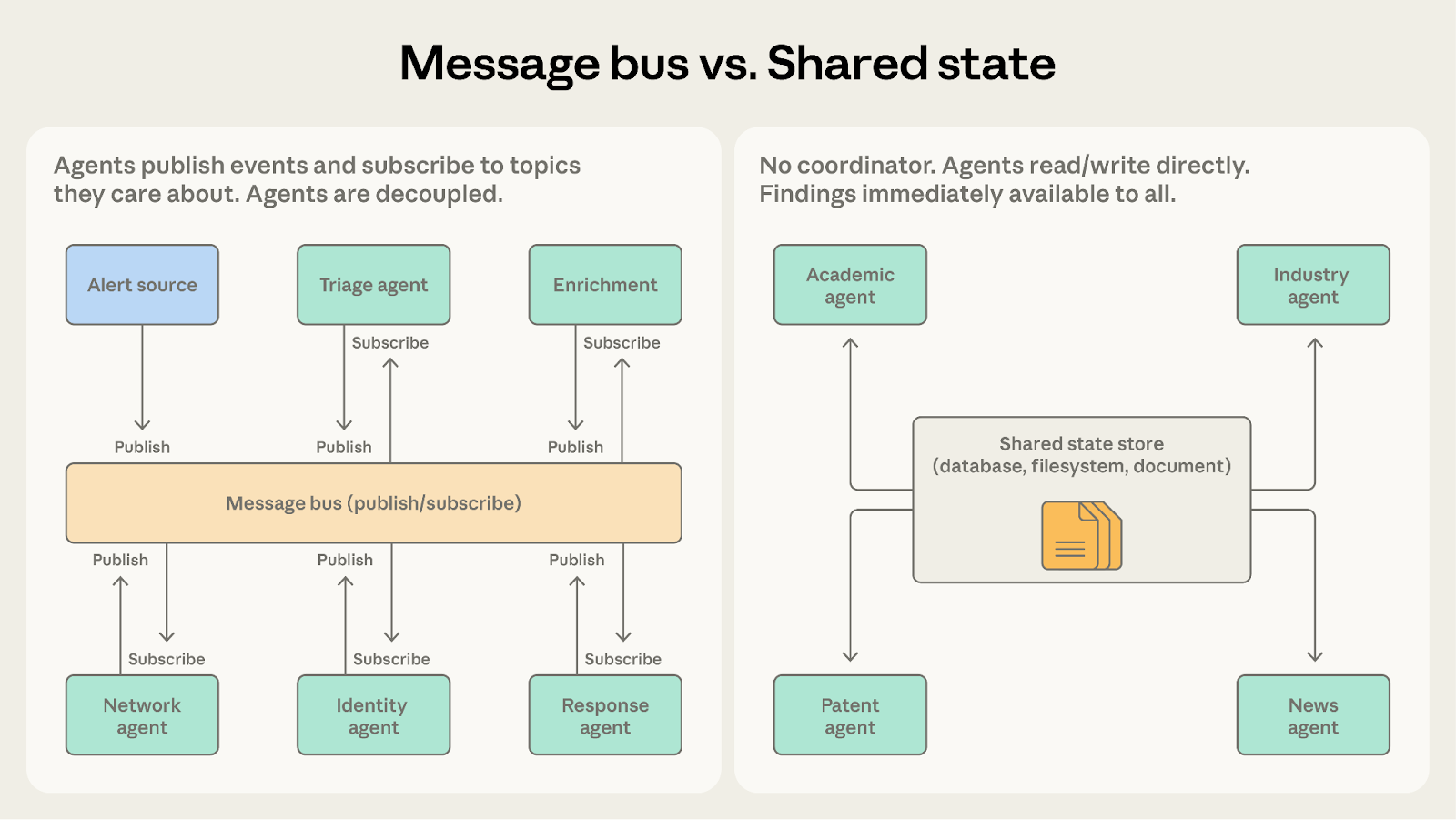
As agent count increases and interaction patterns grow complex, direct coordination becomes difficult to manage. A message bus introduces a shared communication layer where agents publish and subscribe to events.
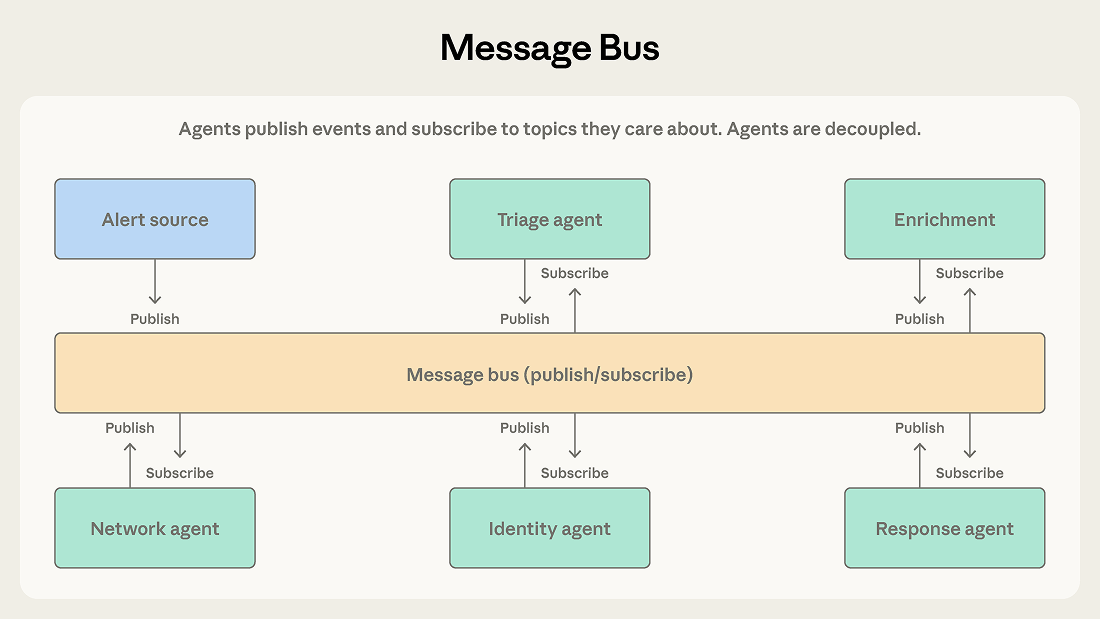
Agents interact through two primitives: publish and subscribe. Agents subscribe to the topics they care about, and a router delivers matching messages. New agents with new capabilities can start receiving relevant work without rewiring existing connections.
A security operations automation system demonstrates where this pattern excels. Alerts arrive from multiple sources, and a triage agent classifies each by severity and type, routing high-severity network alerts to a network investigation agent and credential-related alerts to an identity analysis agent. Each investigation agent may publish enrichment requests that a context-gathering agent fulfills. Findings flow to a response coordination agent that determines the appropriate action.
This pipeline suits the message bus because events flow from one stage to the next, teams can add new agent types as threat categories evolve, and teams can develop and deploy agents independently.
Use this pattern for event-driven pipelines where the workflow emerges from events rather than a predetermined sequence, and where the agent ecosystem is likely to grow.
The flexibility of event-driven communication makes tracing harder. When an alert triggers a cascade of events across five agents, understanding what happened requires careful logging and correlation. Debugging is harder than following an orchestrator's sequential decisions.
Routing accuracy is also critical. If the router misclassifies or drops an event, the system fails silently, handling nothing but never crashing. LLM-based routers provide semantic flexibility but introduce their own failure modes.
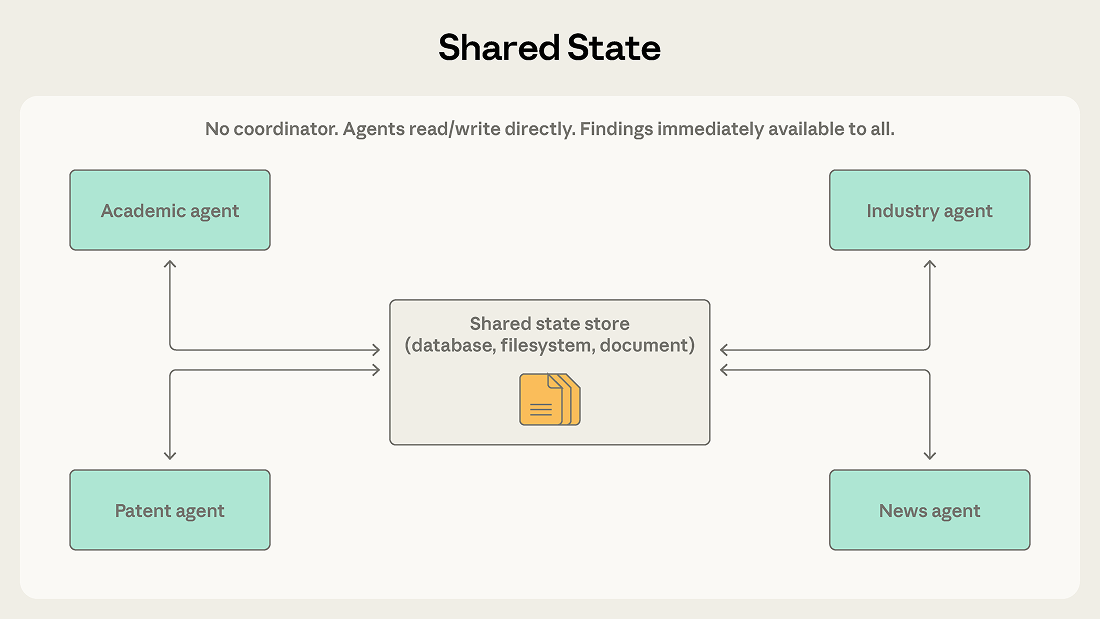
Orchestrators, team leads, and message routers in the previous patterns all centrally manage information flow. Shared state removes the intermediary by letting agents coordinate through a persistent store that all can read and write directly.
Agents operate autonomously, reading from and writing to a shared database, file system, or document. There's no central coordinator. Agents check the store for relevant information, act on what they find, and write their findings back. Work typically begins when an initialization step seeds the store with a question or dataset, and ends when a termination condition is met: a time limit, a convergence threshold, or a designated agent determining the store contains a sufficient answer.
Consider a research synthesis system where multiple agents investigate different aspects of a complex question. One explores academic literature, another analyzes industry reports, a third examines patent filings, a fourth monitors news coverage. Each agent's findings may inform the others' investigations. The academic literature agent might discover a key researcher whose company the industry agent should examine more closely.
With shared state, findings go directly into the store. The industry agent can see the academic agent's discoveries immediately, without waiting for a coordinator to route the information. Agents build on each other’s work, and the shared store becomes an evolving knowledge base.
Shared state also removes the coordinator as a single point of failure. If any one agent stops, the others continue reading and writing. In orchestrator and message-bus systems, a coordinator or router failure halts everything.
Without explicit coordination, agents may duplicate work or pursue contradictory approaches. Two agents might independently investigate the same lead. Agent interactions produce system behavior rather than top-down design, which makes outcomes less predictable.
The harder failure mode is reactive loops. For example, Agent A writes a finding, Agent B reads it and writes a follow-up, Agent A sees the follow-up and responds. The system keeps burning tokens on work that isn’t converging. Duplicate work and concurrent writes have known engineering fixes (locking, versioning, partitioning). Reactive loops are a behavioral problem and need first-class termination conditions: a time budget, a convergence threshold (no new findings for N cycles), or a designated agent whose job is to decide when the store contains a sufficient answer. Systems that treat termination as an afterthought tend to cycle indefinitely or stop arbitrarily when one agent's context fills.
The right pattern depends on a handful of structural questions about the system. In our previous post, we argued for context-centric decomposition, which divides work by what context each agent needs rather than by what type of work it does. That principle applies here too. The patterns differ in how they manage context boundaries and information flow.
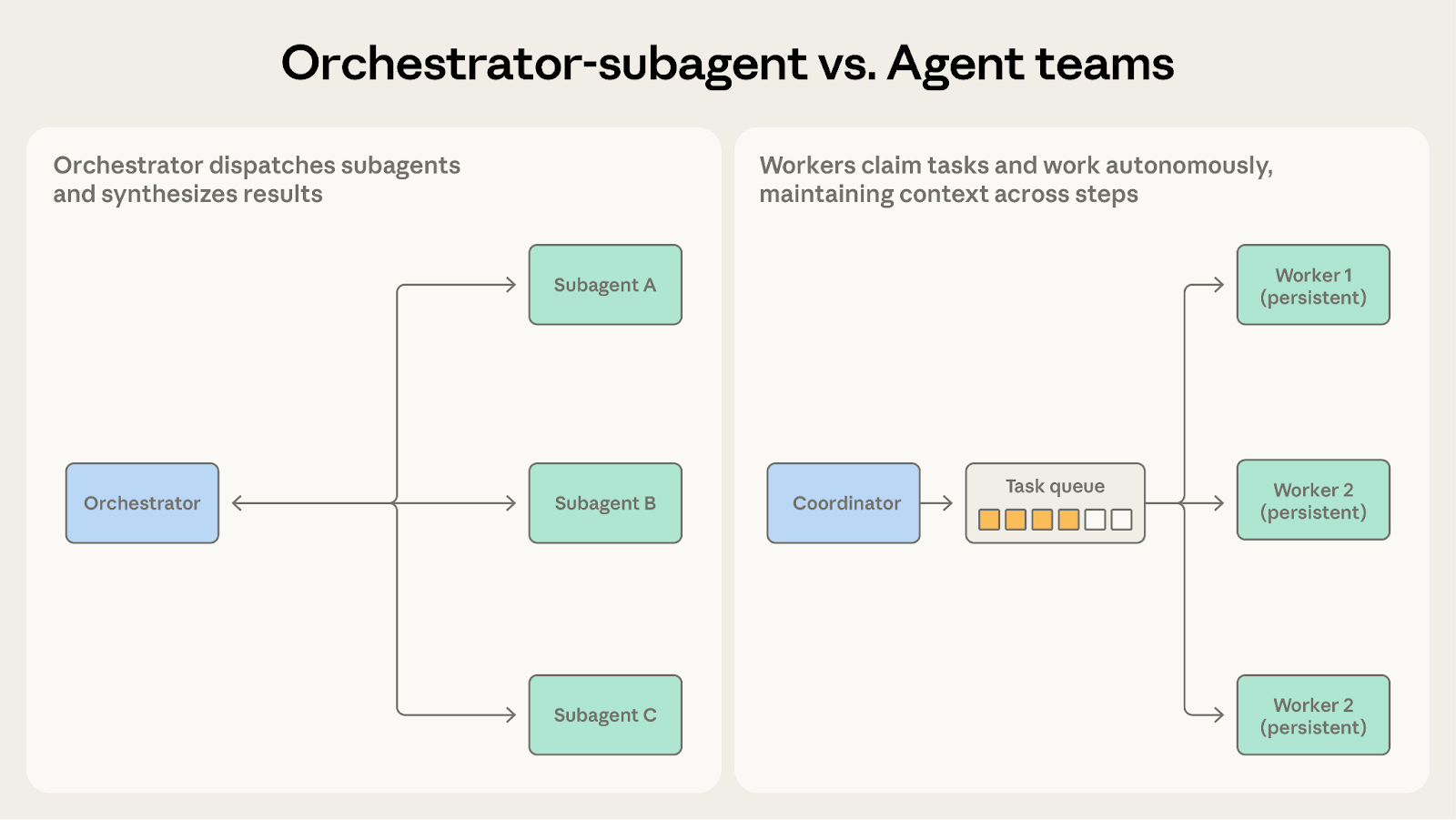
Both involve a coordinator dispatching work to other agents. The question is how long workers need to maintain their context.
When subagents need to retain state across invocations, agent teams are the better fit.
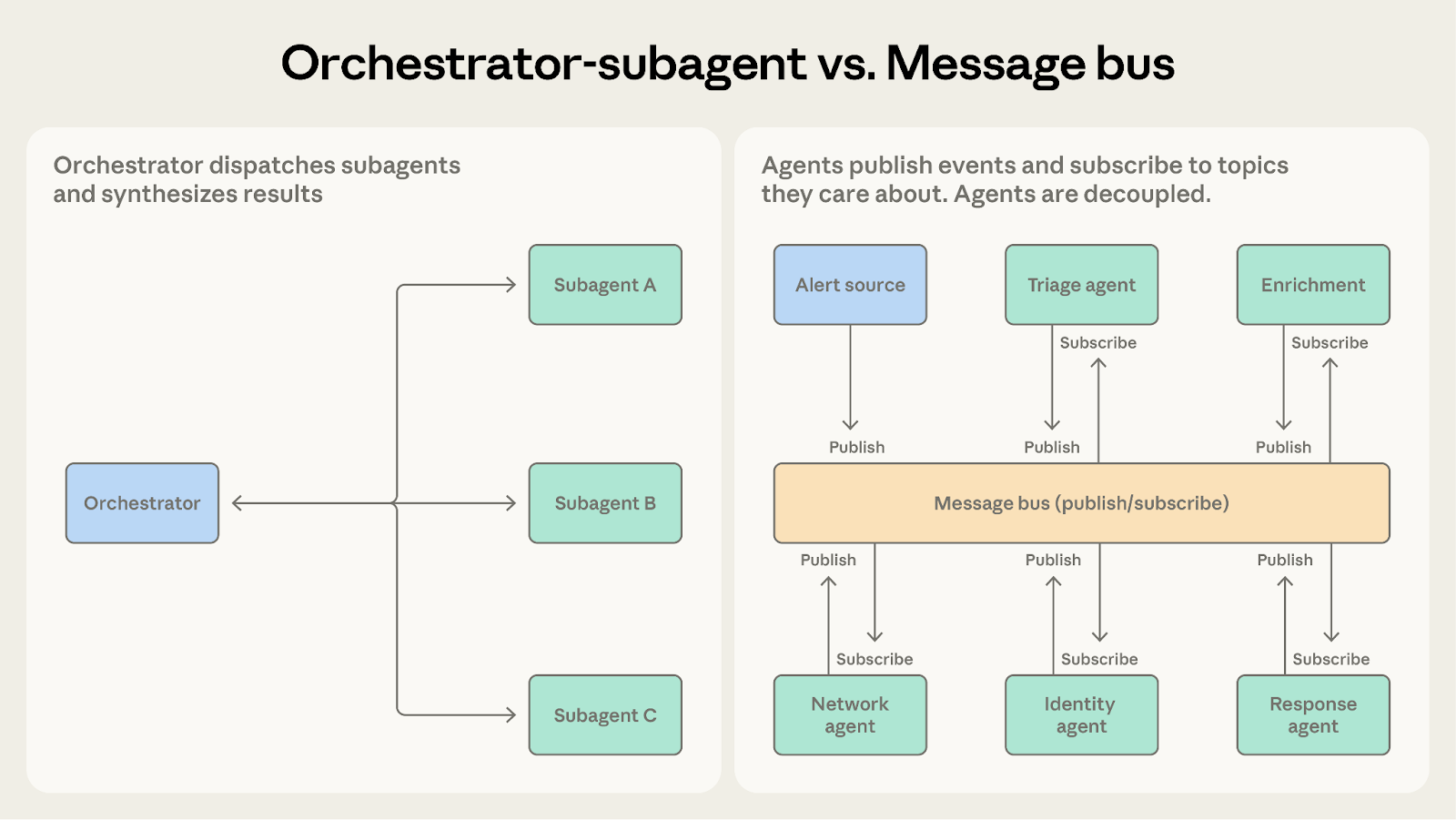
Both can handle multi-step workflows. The question is how predictable the workflow structure is.
As conditional logic accumulates in the orchestrator to handle an expanding variety of cases, the message bus makes that routing explicit and extensible.
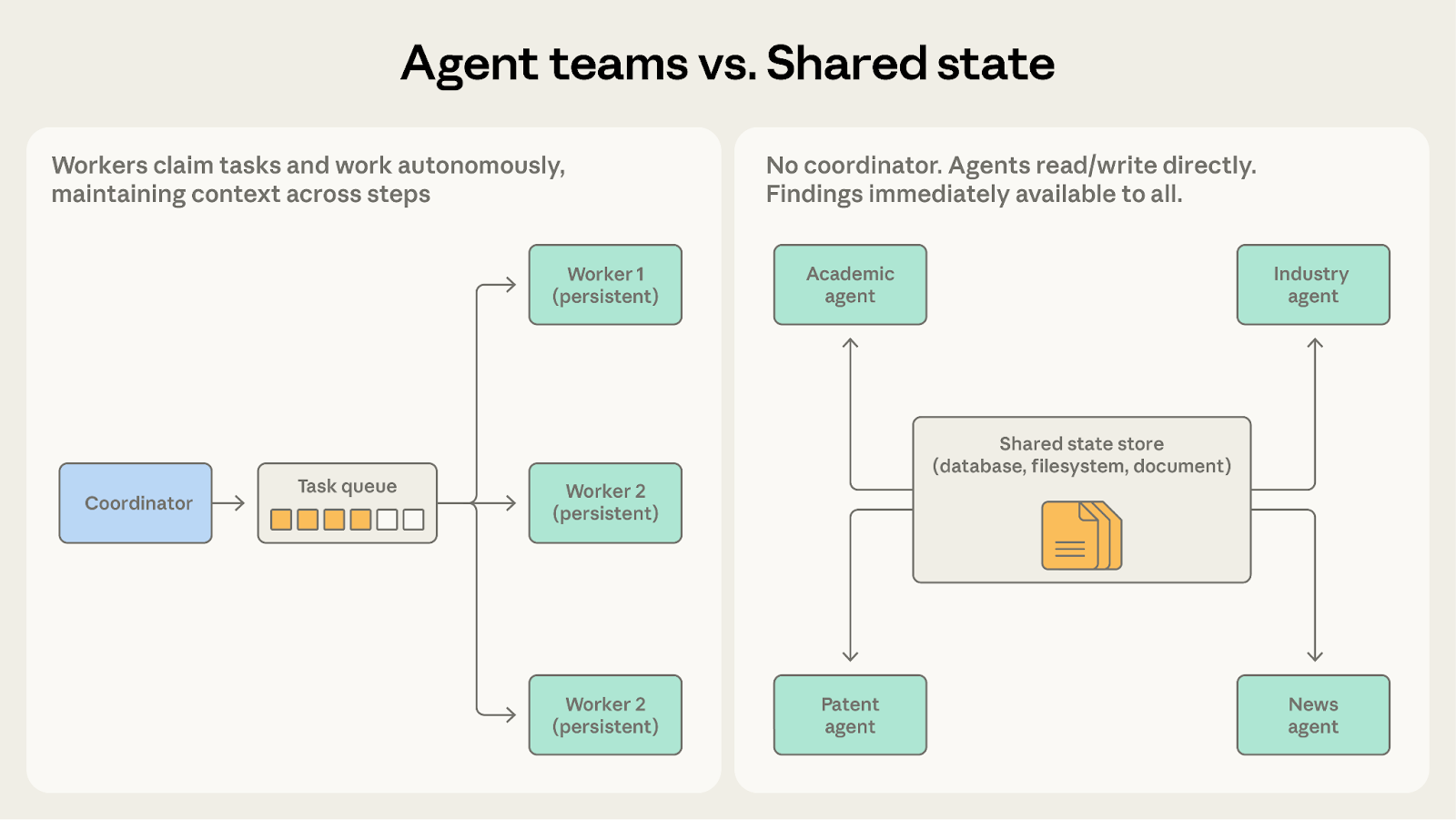
Both involve agents working autonomously. The question is whether agents need each other's findings.
Once teammates need to communicate with each other rather than only share final results, shared state makes that more natural.
Both support complex multi-agent coordination. The question is whether work flows as discrete events or accumulates into a shared knowledge base.
The message bus still has a router, which means a central component decides where events go. Shared state is decentralized. If eliminating single points of failure is a priority, shared state provides that more completely.
If agents in a message bus system are publishing events to share findings rather than trigger actions, shared state is a better fit.
Production systems often combine patterns. A common hybrid uses orchestrator-subagent for the overall workflow with shared state for a collaboration-heavy subtask. Another uses message bus for event routing with agent team-style workers handling each event type. These patterns are building blocks, not mutually exclusive choices.
The following table summarizes when each pattern is appropriate.
For most use cases, we recommend starting with orchestrator-subagent. It handles the widest range of problems with the least coordination overhead. Observe where it struggles, then evolve toward other patterns as specific needs become clear.
In upcoming posts, we will examine each pattern in depth with production implementations and case studies. For background on when multi-agent systems are worth the investment, see Building multi-agent systems: when and how to use them.
Written by Cara Phillips, with contributions from Eugene Yan, Jiri De Jonghe, Samuel Weller, and Erik S.

Get the developer newsletter
Product updates, how-tos, community spotlights, and more. Delivered monthly to your inbox.



