Map your understanding and build lessons from the gaps
Claude Opus 4.6 traces your confusion to its source. It maps what you already understand, finds the specific misconception underneath, and builds personalized learning experiences around it.
Opus 4.6 maps what you already understand before trying to explain anything. It asks diagnostic questions, finds the specific point where your reasoning breaks, and builds the explanation from that gap.
From a single conversation, it produces three artifacts: an interactive lesson built around your misconception, a workbook that applies the concept to your own data, and a concept map connecting forward. Describe the concept you're stuck on and what you do understand. Your prompt doesn't need to be precise — Claude narrows it down from there.
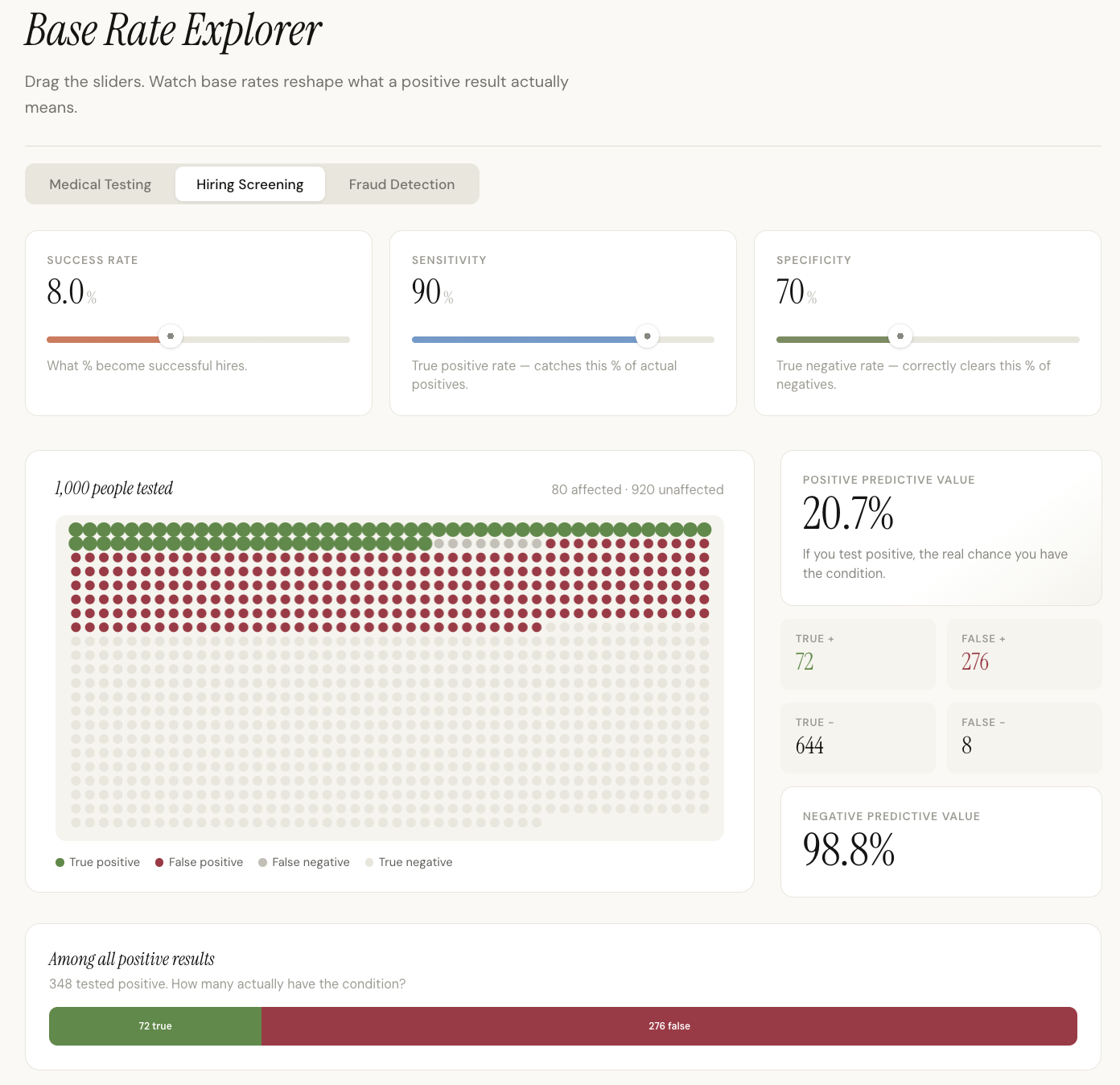
I keep running into “Bayesian reasoning” in things I read—essays, podcasts, even conversations at work. People say “update your priors” or “you’re ignoring the base rate” and I nod along, but I can’t actually follow the logic when it gets specific. I understand basic probability fine. I can calculate odds, I know what a conditional probability is in the abstract. But when someone explains why a 99% accurate test doesn’t mean a 99% chance you’re sick, I lose the thread halfway through.
Help me understand this. Then build me an interactive lesson, a workbook I can use to audit which signals in my hiring pipeline actually predict success, and a concept map connecting it to what I’ll encounter next.
The diagnostic works from conversation alone. If you have data you'd like Claude to apply the concept to, the sections below cover what to upload.

Claude asks diagnostic questions first, probing what you know until it identifies the specific misconception. Then it rebuilds from the gap and produces all three artifacts. Opus 4.6 stays persistent through this entire sequence, and its writing keeps pace—the explanation, lesson, workbook, and concept map all maintain a consistent voice calibrated to your actual comprehension level.
Let me figure out where your understanding is solid and where it breaks.
You said you understand basic probability and conditional probability in the abstract. Quick scenario: a disease affects 1 in 1,000 people. A test is 99% accurate. You test positive. What's the probability you actually have the disease?
[After your response]
You said about 99%. That's the exact misconception I was looking for.
The answer is about 9%. Imagine testing 1,000 people. One has the disease, and the test catches them. But of the 999 healthy people, 1% get false positives. That's about 10 people. So you have 11 positive results, and only 1 is actually sick.
The core confusion: people treat the accuracy of a signal as the probability of the conclusion, without asking how common the thing they're looking for is. A hiring manager sees that 90% of successful hires had a certain trait, so they screen for it. But if 90% of all candidates have that trait, it predicts nothing.
Now let me build you three things you can keep.
[View the interactive lesson]
A simulator where you adjust base rates, test accuracy, and specificity across domains and watch how the ratio of true positives to false positives shifts in real time.
Since you uploaded your spreadsheet, I pulled your team's hiring data directly. Three tabs: your pipeline with base rates at each stage, a signal audit showing which interview criteria actually predict success (your technical assessment moves the needle from 8% to 34%; your culture fit score barely moves it), and a decision framework for evaluating any screening criterion.
[Download: signal-audit-workbook.xlsx]
A one-page visual connecting base rate reasoning to signal detection theory, the prosecutor's fallacy, information gain, and why A/B tests need control groups. Each concept links to the reasoning chain that explains it.
[View the concept map]
Upload your pipeline or screening data and ask Claude to separate real signals from noise. Opus 4.6 scans across large files and datasets before responding, so it handles messy real-world numbers without oversimplifying.
Here’s my team’s full hiring pipeline from the last 2 years—applications through 12-month retention. Walk me through which interview criteria actually predict success once you factor in the base rates. I especially want to know about our new case study exercise—we added it in Q3 and our hire quality seems better. Is the case study a real signal or are we seeing what we want to see?
Open the workbook in Excel and continue the analysis with Claude in Excel. Claude works directly in a sidebar in Excel—it can read your data, modify formulas, and build on the workbook without leaving your spreadsheet.
I downloaded the signal audit workbook. Can you add a tab that checks whether any of our interview signals are redundant—measuring the same thing as another signal we already screen for? I want to cut the ones that aren’t adding new information.
Connect this concept into a multi-session learning project. Opus 4.6 carries instructions through longer sessions without drifting, so your diagnostic context holds as you move through related topics.
Now that I understand base rates, I want to build out my understanding of the related concepts on the map—signal detection theory, information gain, and the prosecutor's fallacy. Can you create a learning sequence that covers one per session, with a workbook for each?
Opus 4.6 invests in understanding your knowledge structure before trying to change it. The more clearly you describe where your understanding is solid, the faster Claude can locate where it breaks. “I understand basic probability but I can’t follow base rate arguments” is a sharper starting point than “I don’t understand statistics.” The gap between what clicks and what doesn’t is usually where the misconception lives.
You don’t need to repeat your requirements or add “and remember to...” reminders. Opus 4.6 follows instructions precisely through the full diagnostic, the artifact construction, and any follow-ups. State what you want upfront and trust that it carries through.
The diagnostic conversation and interactive artifacts work well in Claude.ai chat on your web browser. If you want to build a longer learning project that spans multiple sessions (covering related concepts and building workbooks from different datasets), use Cowork in Claude Desktop [Research Preview]. Opus 4.6 stays persistent across extended projects, and Cowork maintains context across conversations and saves files directly to your machine.