効果的なエージェントを構築する

Anthropic のエンジニアリングチームが、顧客との協業とエージェント構築を通じて得た知見。
Claude を活用して、より効果的に計画、実行、連携する AI エージェントを構築できます。




















優れた推論と人間並みの品質の回答を取得できます。
Claude は、カスタマーサポートからコーディングまで、AI エージェントのシナリオにおいて他のモデルを凌駕します。
Claude の会話スタイルは、AI エージェントとユーザーの間に真の協働をもたらします。
Claude は、誠実さ、ジェイルブレイク耐性、ブランドセキュリティにおいて最も高い評価を得ています。
Anthropic のエンジニアリングチームが、顧客との協業とエージェント構築を通じて得た知見。
コード変更頻度の減少
Claude の強力な AI 機能を既存のアプリケーションに統合し、本番環境レベルのエージェントをより迅速に提供します。
あなたは、カスタマーサポートチケットの分類を専門とする AI アシスタントです。あなたのタスクは、与えられたチケットの内容を分析し、事前定義されたリストから最も適切なカテゴリに割り当てることです。また、その分類の決定理由も説明します。
まず、使用可能なカテゴリを確認しましょう。
<category_list>
{{CATEGORY_LIST}}
</category_list>
次に、分類する必要があるサポートチケットの内容を以下に示します。
<ticket_content>
{{TICKET_CONTENT}}
</ticket_content>
以下の手順に従ってタスクを完了します。
– チケットの内容を注意深く読み、分析します。
– 内容が利用可能な各カテゴリとどのように関連しているかを検討します。
– チケットに最も適切なカテゴリを選択します。
– 推論プロセスの詳細な説明を提供します。
以下の構成を使用して回答します。
<classification_analysis>
このセクションでは、思考プロセスを分解します。
– チケットの内容の中で最も関連性の高い部分を引用します。
– 各カテゴリをリストアップし、それがチケットの内容とどのように関係しているかを注記します。
– 各カテゴリについて、チケットをそのカテゴリに分類することの賛成論と反対論を示します。
– 最も可能性の高いカテゴリ上位 3 つをランク付けします。
</classification_analysis>
<classification>
<category>選択したカテゴリをここに表示</category>
<reasoning>このカテゴリを選択した理由の簡潔な要約</reasoning>
</classification>
分析を徹底的に行い、説明を明確にすることを忘れないでください。目標は、十分に裏付けられた推論に基づいて正確な分類を提供することです。
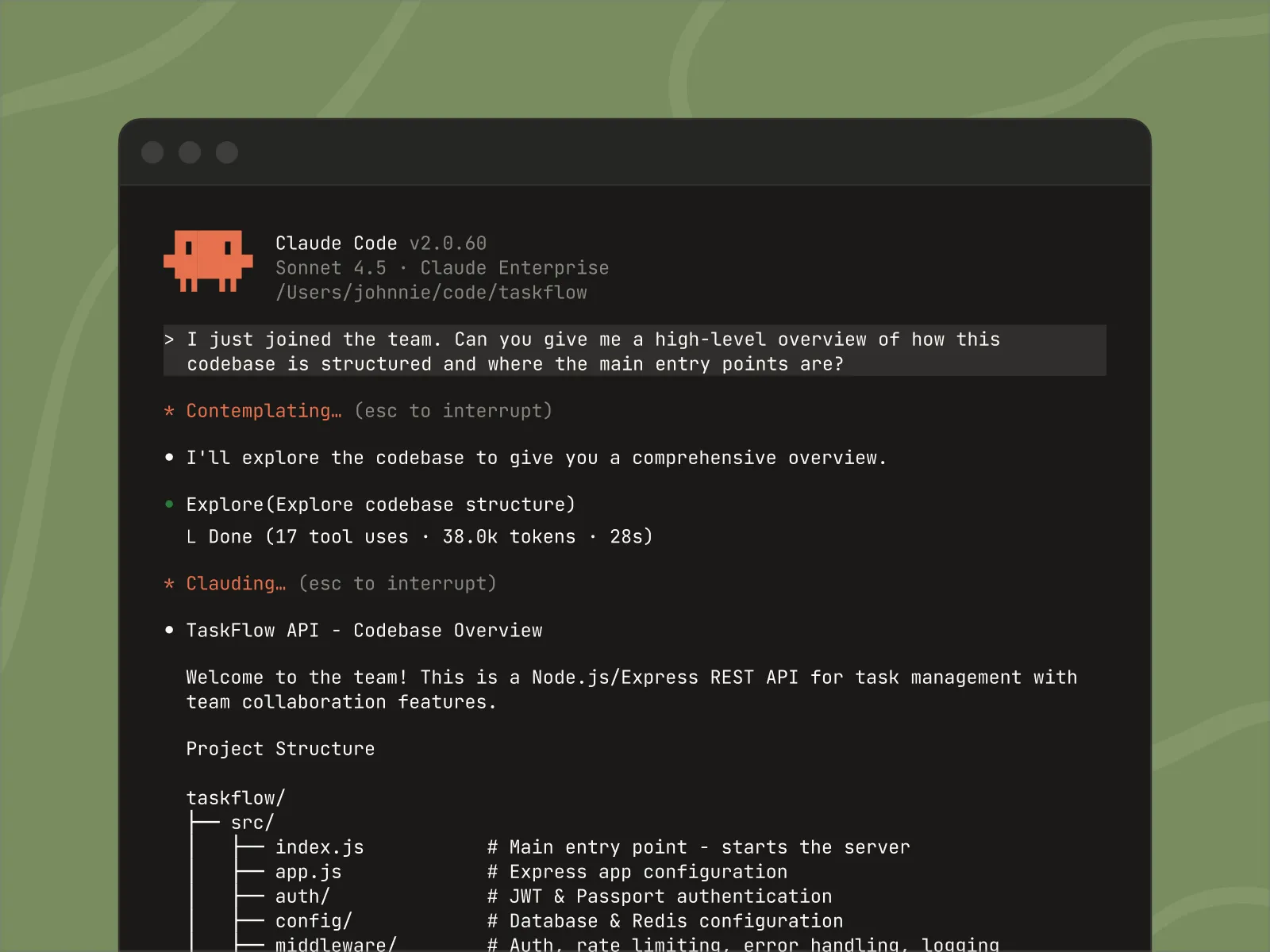
Claude Code はエージェントツールです。開発者は、自分のターミナルから Claude と直接連携し、コード移行からバグ修正に至るまでタスクを委任できます。


"Claude Fable 5 delivers more capable engineering in fewer turns than prior models—handling the complex multi-agent workflows our employees run daily in Claude Code."
"Claude Fable 5 is the highest-scoring model on FrontierBench, Cognition's frontier coding eval. It excels at long-horizon reasoning and generalizes to unfamiliar tools out of the box."